

How to Guides: Search Engine Optimisation
How to Optimize Google My Business Listings?
Oct 22, 2018
What is Google My Business Listings?
Google My Business is a free and easy tool for business local listing in Google Maps.

In the past years, SEO has experienced some of the biggest changes. Everybody wants to know the current rules of Google so that they can be on the first page of Google searches. Strategies have dramatically shifted from bulk of link building to on-page optimization to content marketing and the list is too long to catch the best SEO practice. So, it is necessary to have a full knowledge of how this search engine works and the logic behind these rankings otherwise you cannot appear in the first place on the result pages of Google.
Google works in a simple way and follows three rules to calculate the results. These steps are crawling, indexing, and serving result. These three practices give us the most relevant result and make Google more competitive compared to other search engines.
Google uses an automated program called spiders or web crawlers to discover pages. These crawlers crawl the World Wide Web to classify the best informative page. The computer is programmed in such a way, that it determines which website to crawl and which website to ignore.
The name of the Google’s web crawler is GoogleBot, which retrieves pages on the web and transfers these pages to the Google Indexer. It works in an amazing way. The crawlers send a request to a web server for a website page, download the entire page and then, hand it over to the Indexer. Crawlers are the driver that derive the whole website to fetch the important links, dead links, detect new links, adds them, and update the Google Index which will be used during the next crawl. The crawlers go from one page to another page through internal linking or scan the whole website and build the index and evaluate your website and update the rank in Google’s search result.
Indexing is called the library of Google where billions of books or websites are stored. It is a stock that refers to the collection of pages during the crawl process which created the index. The indexer comprises all the information of the content and the locations of the webpages.
When the user types a query into the search engine, the algorithm scans your search term in the index to find the most relevant pages. In simple terms, the crawling monitors the links and indexing is the practice of addition of webpages into the Google search engine. Indexing is important as Google stores the information or data of the website for later retrieval.
The indexing includes the below details:
Indexing is the database which helps Google to predict the best page from the index to show on the top of the search engine result page when a user types a query.
The most typical situation comes in the third step to identify which pages to show in the Google search from the index. Google ranks the pages according to their scores given to each page based on relevance and importance. There are a number of factors and different ranking signals used by Google to make the page relevant and important. Therefore, it is important to make your webpage crawlable and indexable to keep yourself in the searches.
Result serving is the process of reflecting the best pages onto the first page of the search engine according to the search query. When a keyword is entered into a search box, Google checks their index or database that is the closest match and displays the best result in front of the user in a few seconds.
Google is a like large box where all the information kept, properly indexed, and ranked to know where it is placed. Therefore, it is a complex set of processes, which offers relevant data according to the search query.
Search Engine Includes the following Step to show the result to the Users:
Steps involved:
Step 1: How many pages have been Indexed by Google
Are you ready to know how many pages have been indexed by Google? If yes, then there is a way to check this. Just enter “Site:Yourwebsite.com”. below is the example.
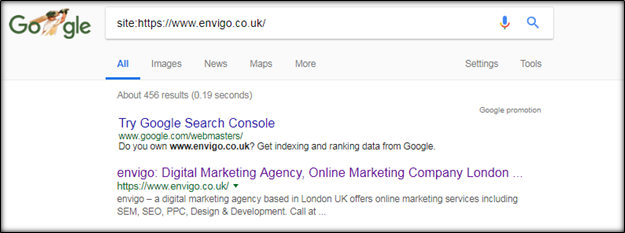
Here, you will get the full detail about an exact number of indexed pages as well as full catalogue of the website. Once you are happy that the search engines are crawling your website correctly.
It is time to monitor how your pages are being indexed.
Step 2: Monitor how the pages are being Indexed
There are three ways to know that are:
1. Run a Google Search: put “cache:yourwebsite.com” and enter.

2. Click through Google Search Result: Whenever your website is visible on search engine result page. You can check the cache of the page by clicking on cached button.
3. Use a bookmarklet: You can bookmark your website in chrome. Create a bookmark and add this as location:

Through caching, you can easily come to know that your page is being cached regularly and you can check that cache covers all your content.
Click on text-only version and you can see how google read your website:
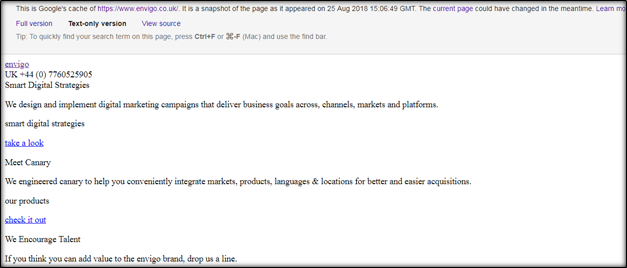
If these are ok, then your certain pages are being crawled and indexed.


How to Guides: Search Engine Optimisation
Oct 22, 2018
What is Google My Business Listings?
Google My Business is a free and easy tool for business local listing in Google Maps.

How to Guides: Search Engine Optimisation
Oct 08, 2018
What is Google Search Console?It is a service provided by Google that helps you to maintain and keep track of your site's presence in Google Search...